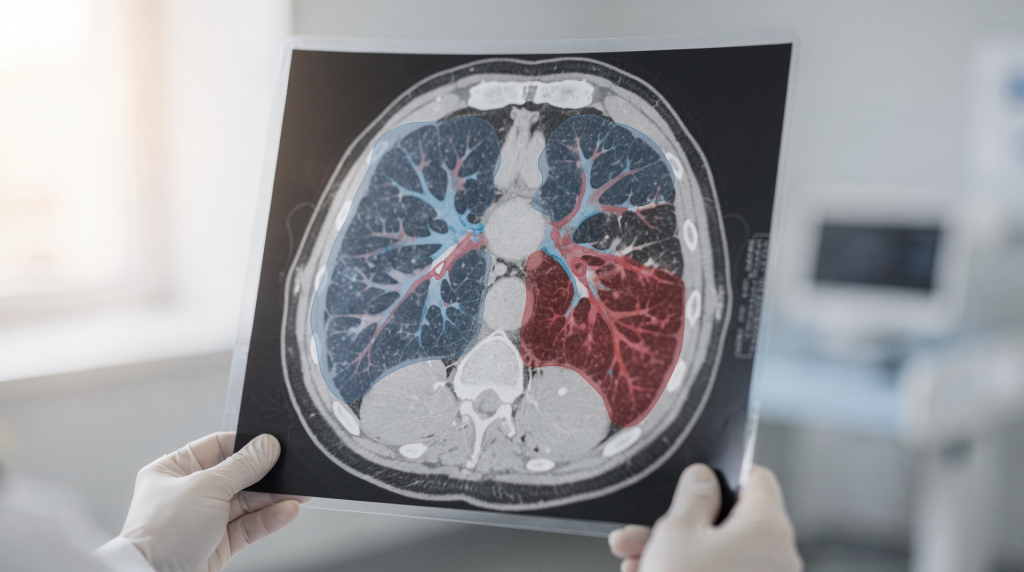
Когда мы запускали первый челлендж по сегментации лёгких, я ещё помнил, сколько часов уходило на ручную обводку контуров в каком-нибудь ITK-SNAP. Сидишь, слой за слоем, поправляешь каждый пиксель, а в голове крутится: «Неужели алгоритм не может сделать это быстрее?» Челлендж как раз и стал тем моментом, когда гипотезы столкнулись с реальными КТ-данными. Это не просто сравнение моделей — это способ понять, где заканчивается кропотливая ручная работа и начинается автоматизация, которой можно доверять.
Почему результаты челленджа важны
Без качественной сегментации лёгочных полей невозможно строить объёмные измерения, искать патологические изменения или готовить данные для более сложных моделей. Это фундамент. Когда я только начинал экспериментировать с пороговой обработкой, казалось, что выделить лёгкие — простая задача. Но стоило взять сканы с эмфиземой, выпотом или артефактами движения, и простые методы начинали сыпаться. Челленджи по сегментации дают редкую возможность сравнить классические подходы, нейросети и полуавтоматические инструменты в одинаковых условиях — на одних и тех же данных, с едиными метриками. Именно здесь становится видно, какие решения переживают встречу с реальной клинической вариабельностью, а какие остаются красивыми графиками в презентации.
Для Lola11 эта тема не просто профильная — она выросла из практики. Сайт начинался как площадка для разметки лёгких на томограммах, и теперь здесь обсуждают, как ИИ меняет анализ медицинских изображений. Поэтому результаты челленджа для нас — не абстрактный бенчмарк, а прямое продолжение того, с чего всё начиналось: как превратить алгоритм в рабочий инструмент врача.
Что обычно оценивают в челлендже по сегментации лёгких
В любом подобном соревновании задача одна: выделить лёгочные поля максимально точно и стабильно на всём объёме КТ. Но дьявол кроется в деталях. Когда я помогал формировать разметку для челленджа, мы спорили о том, где именно проходит граница лёгкого в области корня, как быть с плевральными наслоениями и стоит ли включать трахею. Эти «мелочи» потом напрямую влияют на метрики и, что важнее, на клиническую применимость.
Основные критерии качества
- Точность границы — насколько контур совпадает с анатомией, особенно в зонах сложной геометрии, таких как рёберно-диафрагмальные синусы.
- Полнота сегментации — не «срезает» ли алгоритм апикальные и базальные отделы. Это частая проблема: модель может хорошо отрабатывать средние срезы, но терять верхушки или самые нижние участки лёгких.
- Устойчивость к артефактам — как модель ведёт себя при шуме, неполном вдохе, металлических имплантах. Помню случай, когда отличная по метрикам сеть полностью теряла лёгкое у пациента с плевральной дренажной трубкой — просто потому, что в обучающей выборке таких примеров не было.
- Скорость работы — насколько метод подходит для реального потока исследований. Если сегментация одного исследования занимает минуты, это приемлемо; если десятки минут — в клинике такой инструмент не приживётся.
- Повторяемость — одинаково ли алгоритм работает на разных сканерах и протоколах. Это критично, потому что в реальной жизни томограммы приходят с разных аппаратов, с разными ядрами реконструкции и толщиной среза.
Какие подходы показали себя лучше
Эволюция методов в челленджах обычно идёт по одному сценарию: простые алгоритмы хороши как стартовая точка, но на сложных данных уступают нейросетям. Когда я только начинал, то пробовал пороговую обработку с последующей морфологией — на чистых сканах работало прилично, но стоило появиться массивному выпоту или выраженной эмфиземе, и маска рассыпалась. Активные контуры чуть улучшали границу, но требовали ручной инициализации, а это сводило на нет идею автоматизации.
На практике сильнее всего выглядят свёрточные модели, особенно архитектуры семейства U-Net. Они лучше удерживают форму органа за счёт анализа контекста на разных масштабах. В наших экспериментах U-Net с вниманием (attention gates) стабильно обходил классические методы на 5–7% по Dice, а главное — не проваливался на краевых случаях. Гибридные схемы, где нейросеть комбинируется с постобработкой на основе активных контуров, тоже показывают хорошие результаты, но требуют более тонкой настройки пайплайна.
Сравнение подходов
| Подход | Сильные стороны | Слабые стороны | Где уместен |
|---|---|---|---|
| Пороговая обработка | Простота, скорость | Плохо работает при шуме и нестандартной анатомии | Черновая сегментация |
| Регионы и связные компоненты | Логичная интерпретация, минимум вычислений | Зависимость от настроек и качества снимка | Подготовка маски |
| Активные контуры | Хорошо уточняют границу | Чувствительны к инициализации | Полуавтоматическая доработка |
| U-Net и подобные CNN | Высокое качество, адаптация к данным | Нужны размеченные данные и контроль переобучения | Автоматическая сегментация |
| Гибридные схемы | Сочетают стабильность и точность | Требуют настройки пайплайна | Клинические сценарии |
Почему ручная разметка проигрывает по масштабируемости
Я не понаслышке знаю, сколько времени отнимает ручная сегментация. На разметку одного КТ-исследования грудной клетки с шагом в 1–2 мм может уйти от 40 минут до полутора часов — в зависимости от сложности случая и опыта врача. Умножьте это на поток в 20–30 исследований в день, и станет ясно, почему полностью ручной подход не масштабируется. Ручная разметка остаётся незаменимой для создания эталонной выборки, обучения моделей и контроля качества, но в ежедневной практике она — узкое горлышко.
Челлендж как раз и демонстрирует этот разрыв. В лабораторных условиях можно добиться ювелирной точности вручную, но в реальной системе ценятся не только цифры Dice, а скорость, стабильность, интеграция с PACS и предсказуемость результата. Когда алгоритм выдаёт маску за 10 секунд с точностью, сопоставимой с ручной разметкой, это меняет рабочий процесс радиолога.
Что показали лучшие решения
Лучшие решения в сегментации лёгких никогда не состоят из одной модели. Это всегда пайплайн, где каждый этап решает свою задачу. Сначала данные очищаются и нормализуются: я обычно привожу значения Хаунсфилда к единому окну, убираю кушетку и другие неанатомические объекты. Затем работает основной сегментатор, а после него включается постобработка: удаление случайных фрагментов, заполнение разрывов, сглаживание контуров, контроль топологии. Без этого даже сильная нейросеть может выдать маску с дырками или «островами» в области трахеи.
Типичный рабочий пайплайн
- Подготовка DICOM-данных.
- Нормализация интенсивностей.
- Аугментация обучающей выборки.
- Обучение сегментационной модели.
- Постобработка маски.
- Визуальная и количественная валидация.
- Интеграция в рабочий процесс.
Такой пайплайн важнее, чем кажется. На тонких срезах, при частичном объёме или после реконструкции с другим ядром модель может начать «срезать» края лёгкого или, наоборот, захватывать грудную стенку. Постобработка сглаживает эти артефакты и делает результат пригодным для клинического использования.
Что делать, если вы хотите повторить такой результат у себя
Если вы планируете внедрить сегментацию в своём проекте, не начинайте с выбора модели. Начните с данных и критериев качества. Я не раз видел, как команды тратили месяцы на обучение сложной сети, а потом обнаруживали, что разметка была неконсистентной, и модель училась не тому. Сначала определите, что именно считается успешной сегментацией: только лёгочные поля или ещё и патологические зоны, нужна ли точная граница плевры, насколько критичны базальные отделы. Ответы на эти вопросы определят и архитектуру, и метрики, и стратегию валидации.
Практические шаги
- Соберите небольшой, но качественно размеченный набор КТ.
- Зафиксируйте единые правила аннотации.
- Проверьте данные на артефакты, пропуски и нестандартные протоколы.
- Сравните базовый классический метод и нейросетевую модель.
- Оцените не только метрики, но и клиническую полезность.
- Посмотрите, где алгоритм ошибается чаще всего.
- Проверьте работу на данных с разных сканеров.
На какие ошибки стоит обратить внимание
В сегментации лёгких есть типовые ошибки, которые кочуют из проекта в проект. Их полезно знать заранее, потому что именно они чаще всего портят впечатление от хорошей по цифрам модели. Я составил список проблем, с которыми сталкивался лично.
Частые проблемы
- Пропуск верхушек лёгких при неполном охвате области. Модель может просто не увидеть верхние срезы, если они выходят за пределы стандартного поля реконструкции.
- Смешение лёгкого и плеврального выпота. Алгоритм часто не может отличить безвоздушную лёгочную ткань от жидкости, особенно если выпот массивный.
- Ошибки у пациентов с выраженной эмфиземой. Разрушенная паренхима имеет плотность, близкую к воздуху, и модель может «потерять» границу.
- Нестабильность на низкодозной КТ. Повышенный шум смазывает контуры, и сегментация становится ненадёжной.
- Срыв на артефактах движения. Дыхательные или сердечные артефакты создают двойные контуры, которые сбивают модель с толку.
- Чрезмерное «обрезание» периферии лёгких. Сеть может излишне агрессивно сглаживать границу, теряя субплевральные узелки или тонкие стенки булл.
Если модель регулярно ошибается в одних и тех же местах, не спешите менять архитектуру. Часто причина в разметке, дисбалансе выборки или слишком узком наборе клинических сценариев. Я обычно первым делом проверяю, нет ли систематического смещения в аннотациях — например, все разметчики обводили выпот как лёгкое или, наоборот, исключали его.
Как использовать результаты челленджа в клинике
Главная ценность челленджа — не в красивом графике leaderboard, а в том, что он показывает путь от прототипа к внедрению. Для клиники результат полезен тогда, когда он помогает ускорить просмотр исследований, стандартизировать измерения и снизить зависимость от ручной рутины. Я видел, как автоматическая сегментация сокращала время подготовки к анализу с 15 минут до пары кликов — и это без потери качества.
Что можно внедрять первым
| Сценарий | Польза | Уровень сложности внедрения |
|---|---|---|
| Автосегментация лёгких | Быстрая подготовка маски | Низкий |
| Объёмные измерения | Стандартизация оценки | Средний |
| Предварительная разметка для врача | Экономия времени | Средний |
| Контроль качества исследований | Отбор проблемных случаев | Средний |
| Интеграция в PACS | Встраивание в поток работы | Высокий |
Почему важно смотреть не только на метрики
Метрики вроде Dice или IoU полезны, но они не отвечают на главный вопрос врача: помогает ли модель работать быстрее и безопаснее. Бывает, что два решения дают близкие цифры, но одно стабильно работает в потоке, а другое ломается на редких, но клинически важных исследованиях. Я вспоминаю случай, когда модель с Dice 0.96 на тестовой выборке полностью провалилась на пациенте с гигантской буллой — просто потому, что таких примеров не было в обучающей выборке. А ведь именно такие случаи и важны в клинике.
Поэтому при оценке результатов челленджа я всегда смотрю на три вещи: качество границы, устойчивость на разных типах данных и пригодность к реальному рабочему процессу. Если модель не встраивается в PACS или требует ручной коррекции в 20% случаев, её практическая ценность резко падает, какой бы ни была метрика.
Что дают классические методы сегодня
Хотя в центре внимания обычно находятся нейросети, классические методы не потеряли ценности. Пороговая обработка, активные контуры и региональные подходы я до сих пор использую как быстрый baseline, инструмент для первичной очистки или способ проверить, действительно ли сложная модель даёт выигрыш. Иногда оказывается, что простая пороговая обработка с морфологической постобработкой справляется не хуже сети на стандартных случаях, а работает в разы быстрее. Но как только появляются атипичные данные, классика сдаётся.
На практике именно комбинация методов часто оказывается самым надёжным решением. Это особенно заметно в медицинской визуализации, где редкие ошибки стоят дороже, чем небольшая потеря в скорости. Гибридный подход, где нейросеть делает основную работу, а классический алгоритм подчищает артефакты, даёт наиболее стабильный результат.
Как организовать разметку, если вы строите свой датасет
Если вы планируете собственный проект по сегментации лёгких, не экономьте на правилах аннотации. Я через это проходил: когда четыре разметчика рисуют границу лёгкого по-разному, модель учится усреднённому контуру, который не устраивает никого. Чем раньше команда договорится, что считать границей лёгкого и как обрабатывать спорные зоны, тем меньше будет шума в данных.
Минимальный набор рекомендаций
- Используйте единые инструкции для всех разметчиков.
- Проводите двойную проверку части исследований.
- Храните спорные случаи отдельно.
- Документируйте все исключения.
- Сразу фиксируйте формат хранения данных и масок.
Что важно для дальнейшего развития темы
Следующий логичный шаг после сегментации — это переход к более сложному анализу КТ: выявлению патологий, классификации узлов, объёмным измерениям лёгочной ткани и комбинированным моделям, которые работают уже не только с одной маской, а с клиническим контекстом исследования. Именно поэтому сегментация остаётся фундаментом: без качественного выделения анатомии трудно строить надёжную автоматическую диагностику. Я сейчас исследую, как сегментационные маски могут служить входом для моделей, которые оценивают эмфизему, интерстициальные изменения или динамику узлов — и это гораздо более амбициозная задача, чем просто обвести лёгкие.
FAQ
Чем полезен челлендж по сегментации лёгких на КТ?
Он показывает, какие алгоритмы лучше справляются с реальными КТ-данными, и помогает выбрать подход для научного или клинического проекта.
Что лучше для сегментации лёгких: классические алгоритмы или нейросети?
Для простых задач могут хватить классических методов, но для стабильной работы на разнообразных КТ обычно выигрывают нейросети, особенно U-Net-подобные модели.
Можно ли использовать результаты челленджа напрямую в клинике?
Не напрямую. Сначала нужно проверить модель на своих данных, оценить ошибки, протестировать интеграцию и только потом думать о внедрении.
Почему ручная разметка всё ещё нужна?
Она нужна для создания эталонной выборки, контроля качества и обучения моделей. Полностью заменить её пока нельзя.
На что смотреть при выборе модели?
На точность контура, устойчивость к артефактам, скорость работы, повторяемость и поведение на сложных клинических случаях.